Multimodal Text Style Transfer for Outdoor Vision-and-Language Navigation
Abstract
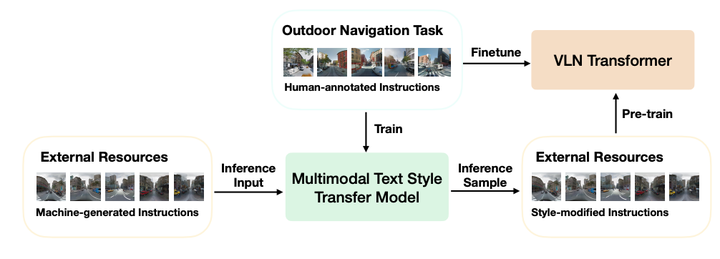
In the vision-and-language navigation (VLN) task, an agent follows natural language instructions and navigate in visual environments. Compared to the indoor navigation task that has been broadly studied, navigation in real-life outdoor environments remains a significant challenge with its complicated visual inputs and an insufficient amount of instructions that illustrate the intricate urban scenes. In this paper, we introduce a Multimodal Text Style Transfer (MTST) learning approach to mitigate the problem of data scarcity in outdoor navigation tasks by effectively leveraging external multimodal resources. We first enrich the navigation data by transferring the style of the instructions generated by Google Maps API, then pre-train the navigator with the augmented external outdoor navigation dataset. Experimental results show that our MTST learning approach is model-agnostic, and our MTST approach significantly outperforms the baseline models on the outdoor VLN task, improving task completion rate by 22% relatively on the test set and achieving new state-of-the-art performance.
Wanrong Zhu
CS Ph.D. Candidate
My research interests include vision-and-language problems and text generation.