VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View
Abstract
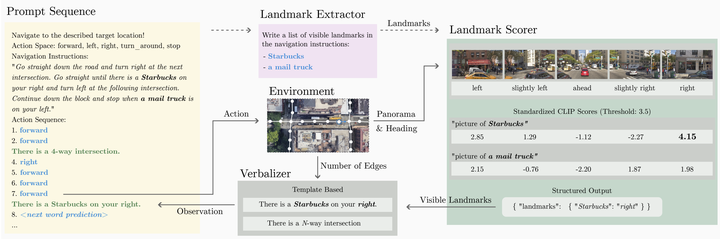
Incremental decision making in real-world environments is one of the most challenging tasks in embodied artificial intelligence. One particularly demanding scenario is Vision and Language Navigation~(VLN) which requires visual and natural language understanding as well as spatial and temporal reasoning capabilities. The embodied agent needs to ground its understanding of navigation instructions in observations of a real-world environment like Street View. Despite the impressive results of LLMs in other research areas, it is an ongoing problem of how to best connect them with an interactive visual environment. In this work, we propose VELMA, an embodied LLM agent that uses a verbalization of the trajectory and of visual environment observations as contextual prompt for the next action. Visual information is verbalized by a pipeline that extracts landmarks from the human written navigation instructions and uses CLIP to determine their visibility in the current panorama view. We show that VELMA is able to successfully follow navigation instructions in Street View with only two in-context examples. We further finetune the LLM agent on a few thousand examples and achieve 25%-30% relative improvement in task completion over the previous state-of-the-art for two datasets.
Wanrong Zhu
CS Ph.D. Candidate
My research interests include vision-and-language problems and text generation.