Abstract
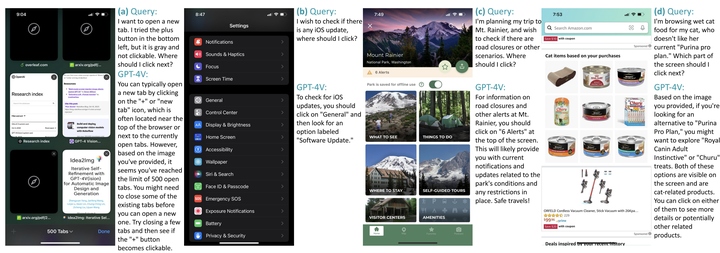
We present MM-Navigator, a GPT-4V-based agent for the smartphone graphical user interface (GUI) navigation task. MM-Navigator can interact with a smartphone screen as human users, and determine subsequent actions to fulfill given instructions. Our findings demonstrate that large multimodal models (LMMs), specifically GPT-4V, excel in zero-shot GUI navigation through its advanced screen interpretation, action reasoning, and precise action localization capabilities. We first benchmark MM-Navigator on our collected iOS screen dataset. According to human assessments, the system exhibited a 91% accuracy rate in generating reasonable action descriptions and a 75% accuracy rate in executing the correct actions for single-step instructions on iOS. Additionally, we evaluate the model on a subset of an Android screen navigation dataset, where the model outperforms previous GUI navigators in a zero-shot fashion. Our benchmark and detailed analyses aim to lay a robust groundwork for future research into the GUI navigation task.
Wanrong Zhu
CS Ph.D. Candidate
My research interests include vision-and-language problems and text generation.