Abstract
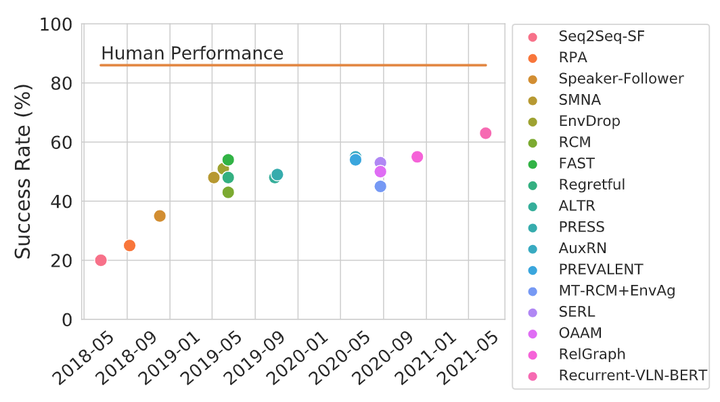
Vision-and-language navigation (VLN) is a multimodal task where an agent follows natural language instructions and navigates in visual environments. Multiple setups have been proposed, and researchers apply new model architectures or training techniques to boost navigation performance. However, there still exist non-negligible gaps between machines' performance and human benchmarks. Moreover, the agents' inner mechanisms for navigation decisions remain unclear. To the best of our knowledge, how the agents perceive the multimodal input is under-studied and needs investigation. In this work, we conduct a series of diagnostic experiments to unveil agents' focus during navigation. Results show that indoor navigation agents refer to both object and direction tokens when making decisions. In contrast, outdoor navigation agents heavily rely on direction tokens and poorly understand the object tokens. The differences in dataset designs and the visual features lead to distinct behaviors on visual environment understanding. Many models claim that they can align object tokens with specific visual targets when it comes to vision-and-language alignments. We find unbalanced attention on the vision and text input and doubt the reliability of such cross-modal alignments.
Wanrong Zhu
CS Ph.D. Candidate
My research interests include vision-and-language problems and text generation.